
Process Science
Hal Varian, the chief economist at Google said in 2009:
The sexy job in the next 10 years will be statisticians. People think I’m joking, but who would’ve guessed that computer engineers would’ve been the sexy job of the 1990s?
The later article with the provocative title “Data Scientist: The Sexiest Job of the 21st Century” (Davenport and Patil 2012) generated lots of attention for this new profession. Indeed, just like computer science emerged from mathematics in the 70-ties and 80-ties, data science is now emerging from computer science, statistics, and management science. However, let’s not forget about processes. As argued in this paper, processes provide the lenses to look at event data from different angles. The focus on data analysis is good, but should not frustrate process-orientation. In the end, good processes are more important than information systems and data analysis. The old phrase It’s the process stupid is still valid. Hence, we advocate the need for process scientists that will drive process innovations while exploiting the Internet of Events (IoE).
Making DS More Concrete: Process Mining
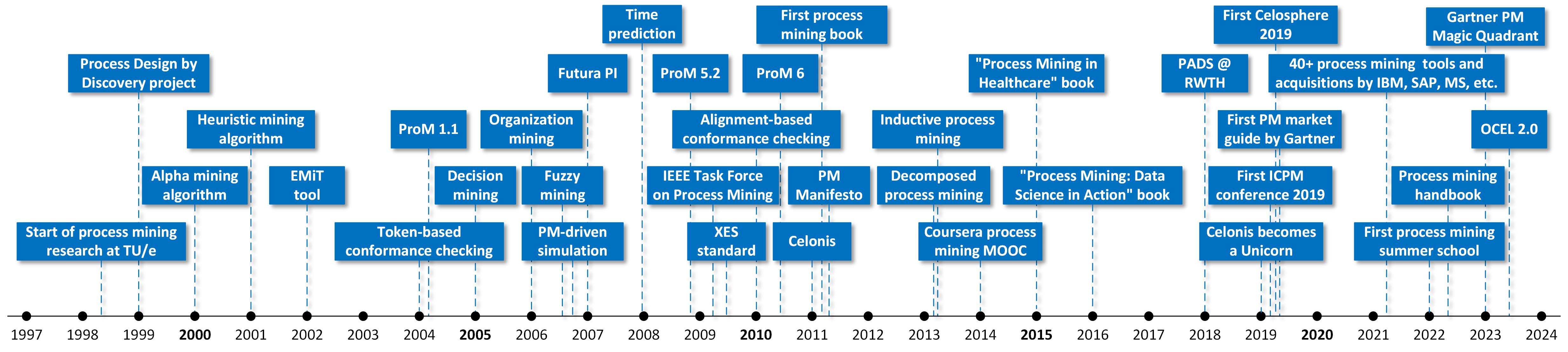
The abundance of event data enables new forms of analysis that facilitate process improvement. Process mining provides a novel set of tools to discover the real process, to detect deviations from some normative process, and to analyze bottlenecks and waste. I started to work on process mining in the late 1990-ties. Discovering a sequential process (e.g., a DFG or Markov chain) is easy. However, it is very difficult to discover a process with concurrency, especially if one only has example traces. None of the then existing approaches were able to handle this setting. This led to the development of the Process Design by Discovery: Harvesting Workflow Knowledge from the Ad-hoc Executions project, which first coined the term process mining. The project was approved in 1999 and funded by BETA. See the process mining timeline showing the development of process mining since its inception in the late 1990-ties until 2024.
{kind=link}
Process Discovery
The first type of process mining is discovery. A discovery technique takes an event log and produces a process model (e.g., Petri net or BPMN model) without using any a priori information. Process discovery is the most prominent process-mining technique. For many organizations it is often surprising to see that existing techniques are indeed able to discover real processes merely based on example behaviors stored in event logs.
Conformance Checking
The second type of process mining is conformance. Here, an existing process model is compared with an event log of the same process. Conformance checking can be used to check if reality, as recorded in the log, conforms to the model and vice versa.
Performance Analysis
State-of-the-art conformance checking techniques create so-called alignments between the observed event data and the process model. In an alignment each case is mapped onto the closest path in the model, also in case of deviations and non-determinism. As a result, event logs can always be replayed on process models. This holds for both discovered processes and hand-made models. Next to showing deviations, alignments can also be used to reveal bottlenecks using timestamps of events. Hence, process mining provides novel forms of performance analyses that combine event data with process-centric visualizations.
Possibilities Are Endless!
The above types of analysis are just examples of process mining techniques. Anything that involves the confrontation between behavioral models and event data is included. Once modeled behavior and real behavior are aligned anything is possible, including online prediction, automated process improvement, resource recommendation, etc.
See http://www.processmining.org/ and slides on how to get started.